Wie auch zur Europawahl 2024 habe ich für die vorgezogene Bundestagswahl 2025 geprüft, wie sich die Parteien zu den Wahl-O-Mat-Thesen positionieren, ob sich die Parteien überhaupt noch unterscheiden, welche Forderungen eher von rechts/links unterstützt werden und wie komplex ihre Begründungstexte ausfallen.
Der Wahl-O-Mat als die bekannteste Hilfe zur Wahlentscheidung ist datenanalytisch interessant, weil die Fragen durch ein unabhängiges Team entstehen und von allen Parteien selbst beantwortet werden. Dadurch haben wir ein gutes Vergleichsmaterial parteipolitischer Ansichten. Allerdings muss auch klar sein: Bewertet die Ergebnisse nicht über! Mit 38 Fragen und nur drei Antwortoptionen lässt sich die parteipolitische Realität natürlich nicht in Gänze abbilden. Die hier gezeigten Ergebnisse können maximal eine Annäherung an die Realität bzgl. der Wahl-O-Mat-Thesen des jeweiligen Jahres sein. Folgende Analysen habe ich durchgeführt:
- Inhaltliche Analyse der Positionierungen zu den Wahl-O-Mat-Thesen
- Thesen-Heatmap: Wie haben sich die Parteien zu den Wahl-O-Mat-Fragen positioniert?
- Thesen-Netzwerk: Welche Thesen sind eher linke/rechte Forderungen?
- Die Parteiverwandtschaft
- Heatmap der Parteiverwandtschaft: Wie hoch ist die Übereinstimmung zwischen den Parteien in Prozent?
- Netzwerk der Parteiverwandtschaft: Interaktive & visuelle Darstellung
- Analyse der Sprachkomplexität: Wie komplex ist die von den Parteien verwendete Sprache in ihren Begründungstexten?
1. Positionierungen der Parteien zu den Wahl-O-Mat-Thesen
Zunächst einmal habe ich alle Antworten der Parteien in einer Heatmap dargestellt und mathematisch ordnen lassen. In der folgenden Abbildung stehen die Parteien am rechten Rand, darunter die Themen zur Bundestagswahl 2025. Der Schnittpunkt von Spalte und Zeile ist eine Zelle, welche durch ihre Färbung die jeweilige Abstimmung zeigt. Die Parteien und Themen wurden durch eine Clusteranalyse automatisch sortiert, sodass ähnliche Elemente möglichst nah beieinander stehen.
Dabei kristallisiert sich grob das Parteienspektrum heraus: (Rechts-)konservative Parteien befinden sich unten, die eher linken Parteien oben. Am Muster der farbigen Zellen erkennt man zudem, dass die ersten 28 Wahl-O-Mat-Thesen relativ stark polarisieren: Wohingegen die ersten 15 Thesen von den linken Parteien auf Ablehnung stoßen (orangener Block oben links) und die darauffolgenden 13 auf deren Zustimmung (grüner Block oben mittig), verhalten sich die (rechts-)konservativen Parteien weitgehend entgegengesetzt. Die letzten 10 Fragen scheint die Lager weniger deutlich zu trennen.
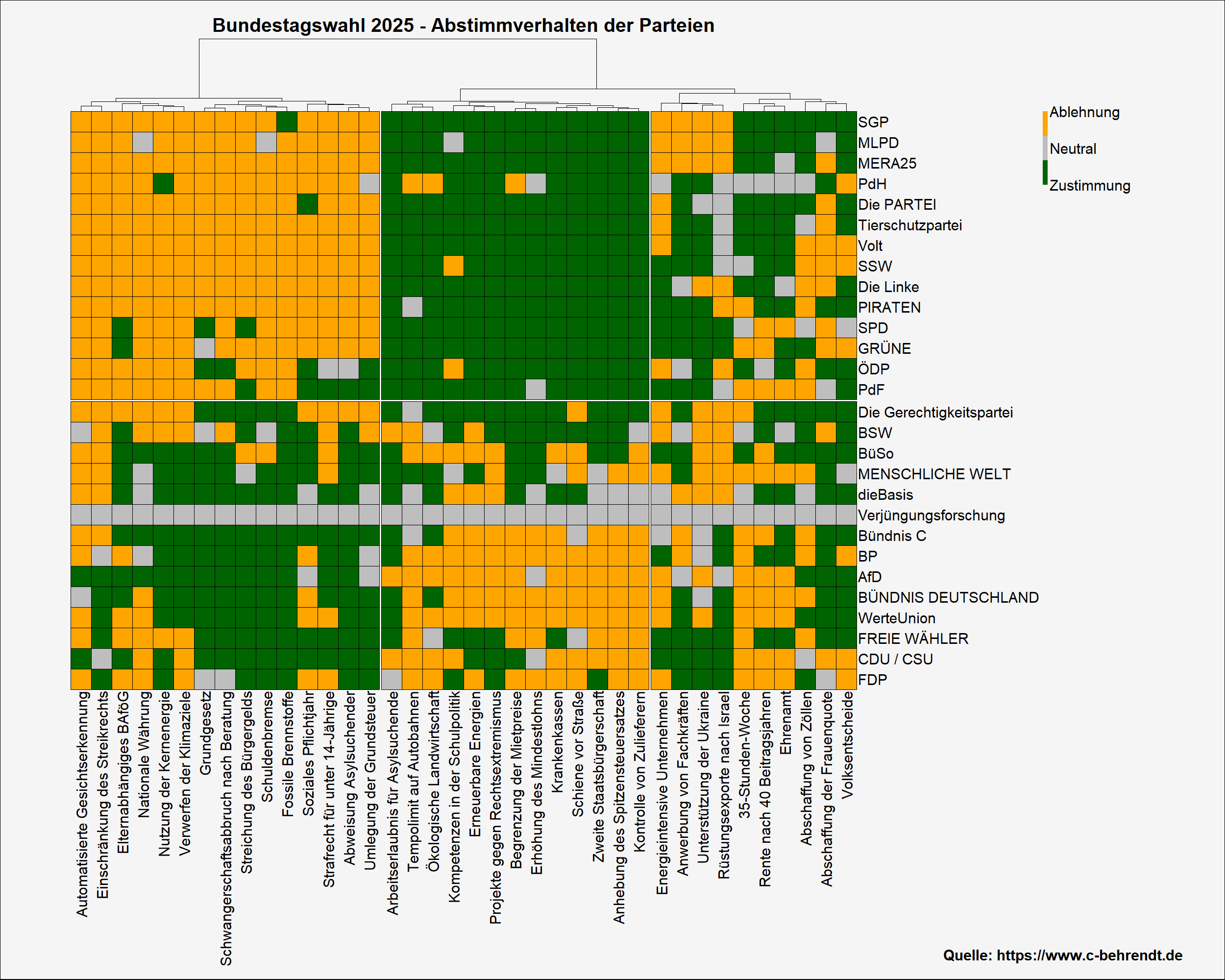
Typisch rechte – typisch linke Thesen? Wer stimmt welchen Themen zu?
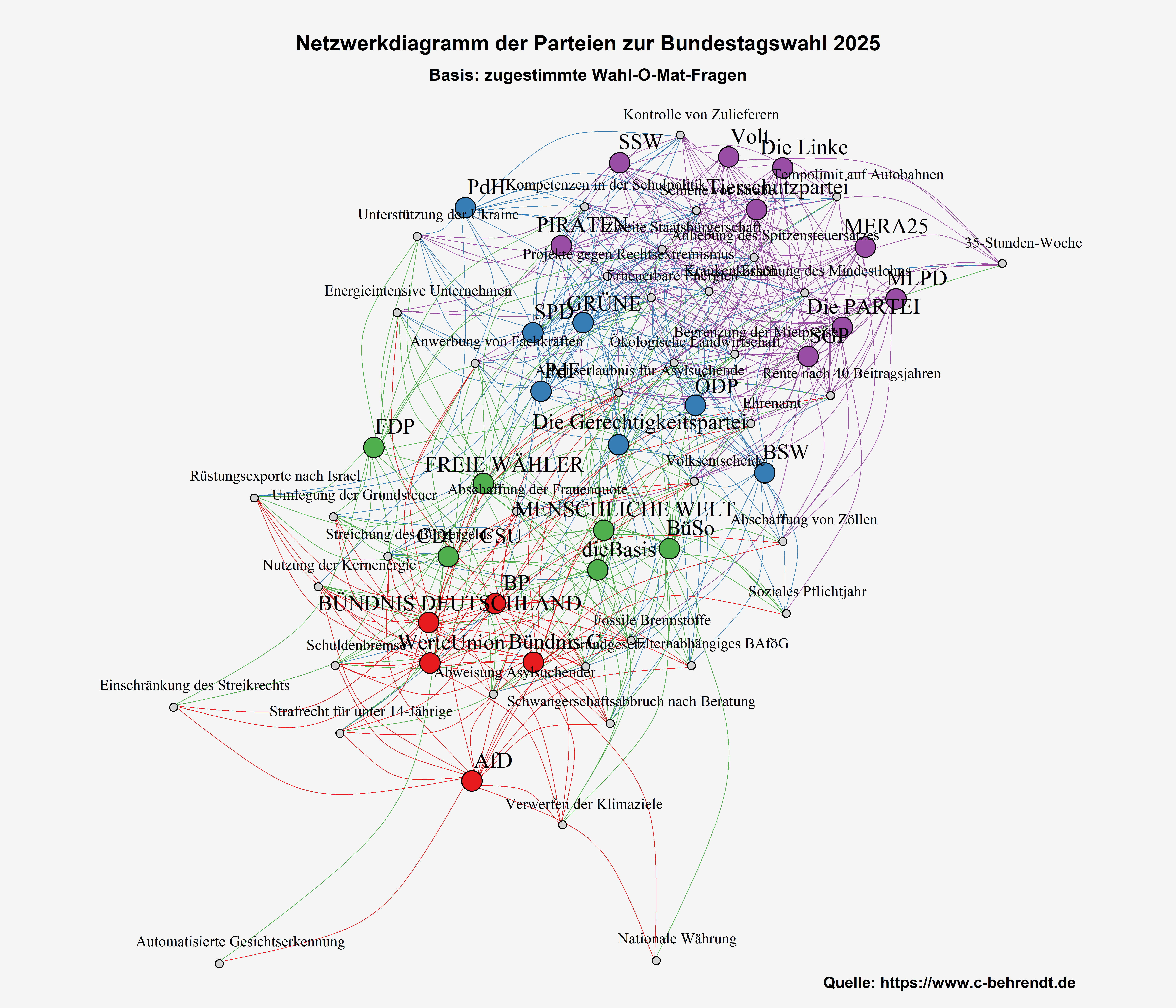
Die sich oben abzeichnende Polarisierung zwischen den Themen lässt sich wunderbar in einem Netzwerkdiagramm prüfen. Im Prinzip ist das nichts anderes als eine hübsche – im zweidimensionalen Raum dargestellte – Beziehung zwischen Datenpunkten. Dabei steht jeder große Punkt für eine Partei. Rundherum befinden sich zudem viele kleine Punkte – diese repräsentieren die Wahl-O-Mat-Thesen zur Bundestagswahl 2025. Die Verbindungslinien zeigen auf, welche Partei einer These zugestimmt hat. Das System ordnet nun auf Basis mathematischer Regeln alle Punkte im Raum so an, dass ähnliche Punkte möglichst nah beieinander liegen. Dabei entsteht folgendes Bild:
Auch hier lässt sich das Parteispektrum einigermaßen gut ablesen. Das Bündel linker Parteien am oberen Rand (lila), die konservativ bis rechten Parteien unten (rot) und die anderen irgendwo dazwischen. Die linken Parteien stimmen eher der 35-Stunden-Woche und einem höheren Spitzensteuersatz zu, wohingegen Themen wie die automatisierte Gesichtserkennung oder die nationale Währung bei den (rechts-)konservativen Parteien zu finden sind. Ein eher mittig positioniertes Thema (z.B. Volksentscheide, Abschaffung von Zöllen) deutet darauf hin, dass es auf eine relativ breite Zustimmung trifft.
2. Die Parteienverwandtschaft: prozentuale Ähnlichkeiten zwischen den Parteien
Oben haben wir gesehen, dass es zwischen den Parteien systematische Überschneidungen gibt. Doch wie stark fallen diese genau aus? Um das herauszufinden, vergleiche ich ihre Antworten auf die 38 Thesen und vergebe Punkte für vollständige und teilweise Übereinstimmungen. Die Berechnung basiert auf der Methodik des Wahl-O-Mat selbst: Je ähnlicher zwei Parteien eine Frage beantworten, desto mehr Punkte erhält dieses Duo:
| Szenario | Punktzahl |
| Volle Übereinstimmung (z.B. beide stimmen zu) | 2 |
| Teilweise Übereinstimmung (z.B. eine Zustimmung, eine Neutral) | 1 |
| Keine Übereinstimmung (z.B. eine Zustimmung, eine Ablehnung) | 0 |
Weil es auch beim diesjährigen Wahl-O-Mat wieder 38 Fragestellungen gibt, lassen sich also maximal 76 Punkte erreichen (38*2=76). Das Ganze wird in Prozent umgerechnet und anschließend in einer sogenannten Heatmap dargestellt. Hier werden alle Parteien einander gegenübergestellt und entsprechend ihrer Ähnlichkeit angeordnet und eingefärbt. Je ähnlicher, desto gelber die Farbe. Das dazugehörige linienartige Dendrogramm zeigt, welche Parteien als besonders ähnlich gelten und zu einer Gruppe zusammengefasst werden können.
Beim Betrachten des Diagramms sticht besonders der große, hellgelbe Zellhaufen unten links ins Auge. Er zeigt die hohe Übereinstimmung zwischen den zahlreichen Parteien des linken Spektrums. Im Gegensatz dazu ist die hellgelbe Fläche oben rechts deutlich kleiner. Hier werden die (rechts-)konservativen Parteien einander gegenübergestellt. Dass ihre Fläche kleiner und weniger intensiv gefärbt ist, deutet darauf hin, dass es in diesem Lager weniger Parteien gibt und ihre Ähnlichkeit untereinander geringer ist als im linken Spektrum.
Dies legt nahe, dass das linke Lager nicht nur mehr, sondern auch tendenziell homogenere Parteien aufweist als das (rechts-)konservative. Diese Struktur könnte sich auch auf Wahlergebnisse auswirken: Während die Stimmen der linken Wählerschaft auf viele Parteien verteilt werden, konzentrieren sich die Stimmen im rechten Lager auf wenige Parteien. Dadurch könnte es für die (rechts-)konservativen Parteien einfacher sein, hohe Wahlergebnisse zu erzielen.
Auch hier erfolgt die automatische Anordnung durch eine sogenannte Clusteranalyse. Der Algorithmus bildet dabei Gruppen („Cluster“) von Parteien, die innerhalb der Gruppe möglichst ähnlich und zwischen den Gruppen möglichst unterschiedlich sind – also eine Art Parteiverwandtschaft. Dadurch werden sie im Diagramm so angeordnet, dass ähnliche Parteien möglichst nah beieinander stehen. Visualisiert wird das Ergebnis zudem als linienartiges Dendrogramm direkt unter der Diagrammüberschrift. Diese Verbindungen zeigen, welche Parteien sich besonders nah sind. Umso ähnlicher sie sich sind, desto näher findet die Verbindung am Diagrammrand statt. Gelesen wird es wie folgt:
Die schwarze Linie direkt unter der Überschrift zeigt, dass das System alle Parteien der x-Achse in zwei Gruppen aufteilt: Alle Parteien von SGP bis BSW befinden sich links (rotes + olives Cluster), alle weiteren rechts (grün + violett). Innerhalb dieser beiden Gruppen sucht das System nun wieder möglichst ähnliche Parteien und verbindet auch diese wieder mit Linien. So befinden sich bspw. alle zwischen SGP und den PIRATEN im roten Cluster. Übergeordnet gehören diese Parteien also ins große linke Lager, sind sich untereinander aber ähnlicher als gegenüber jenen im benachbarten Cluster (oliv).
Innerhalb des roten Clusters wird nun erneut geprüft, wo die größten Ähnlichkeiten zu finden sind. Beispielsweise werden die SGP und die MLPD mit einer sehr flachen Linie verbunden, was auf ihre hohe Übereinstimmung hinweist. Zu diesem Duo stoßen als nächstes das ebenfalls recht homogene Trio aus MERA25, Die LINKE und Die PARTEI.
Das Netzwerkdiagramm der Parteiverwandtschaft
Auch für die prozentualen Übereinstimmungen der Parteien lohnt sich die visualisierte Betrachtung in einem Netzwerkdiagramm. Diesmal wähle ich aus dem Datensatz aber nur die besonders starken Parteiverwandtschaften heraus. Das reduziert das unwichtige Rauschen und lässt uns das erkennen, wofür wir hier sind. Dafür werden nur Verbindungen mit mindestens 60 Prozent Übereinstimmung der oben vorgestellten Berechnung berücksichtigt (46 von 76 Punkten). Auch hier liegen wieder Parteien mit einer hohen inhaltlichen Nähe dichter beieinander. Zudem sind sie durch Linien verbunden, deren Stärke und Farbe den Grad der Übereinstimmung unterstreichen.
Wie erwartet zeigt das Diagramm ein großes Bündel linker Parteien, das nur schwach mit dem (rechts-)/konservativen Parteienbündel verbunden ist. Die Stärke und Farbe der Verbindungslinien zeigen zudem, dass zwischen den eher linken Parteien eine deutlich größere Überschneidung existiert als es zwischen den (rechts-)konservativen der Fall ist.
3. Wortanzahl & sprachliche Komplexität der Begründungstexte
Wortanzahl
Zusätzlich zur Beantwortung der Wahl-O-Mat-Thesen konnten die Parteien ihre Entscheidungen mit ausformulierten Texten begründen. Und das machen sie in sehr unterschiedlichem Ausmaß. Wohingegen die FDP die meisten Wörter für ihre Begründungen verwendet, stehen das Bündnis C, der SSW und die BP mit großem Abstand am Ende der Rangfolge.
Sprachliche Komplexität
Nun kann abschließend geprüft werden, wie lesbar diese Begründungstexte geschrieben wurden. Denn es ist kein Geheimnis, dass die Sprache zur Zielgruppe passen sollte. Wenn 75% der Wahl-O-Mat-Nutzer keinen Hochschul- oder Abiturabschluss haben oder eine Partei eine Wählerschaft mit eher niedrigem Bildungsniveau anzusprechen versucht, dann sollte die Sprache kein Akademikerniveau haben.1Diese Thematik ist besonders bei der Linkspartei immer wieder relevant, die zwar Wähler mit niedrigem Bildungsniveau ansprechen möchte, jedoch oft eine komplexe Sprache verwendet.
Will man also wissen, wie komplex ein geschriebener Text ist, greift man in der Forschung auf sogenannte Lesbarkeitsindizes zurück. Einer davon ist der Flesch-Index. Dieser geht davon aus, dass ein Text umso lesbarer ist, je kürzer die Wörter und Sätze sind. Je höher der Flesch-Wert, desto verständlicher erscheint ein Text. Weil dieser Index auch für deutsche Texte verwendbar ist, habe ich dessen Formel2Flesch-Wert = 180 – (Anzahl aller Worte / Anzahl aller Sätze) – (58,5 * (Anzahl aller Silben / Anzahl aller Worte)) in meinen Code integriert und erhielt folgende Ergebnisse:
Die PARTEI erzielte den höchsten Flesch-Index-Wert (59,1). Damit erscheinen ihre Begründungstexte am lesbarsten. Die Texte der PdF liegen am anderen Ende der Rangfolge und erscheinen mit einem Wert von 27,9 deutlich komplexer. Insgesamt nutzen fast alle Parteien eine eher schwer verständliche Sprache. Was angesichts der Komplexität politischer Themen verständlich sein mag, wirft gleichzeitig die Frage auf, ob diese Texte dann auch nachhaltig bei den Zielpersonen ankommen.




